Projekte im Wintersemester 2015/16
Seiteninhalt
Erschließungs- und Visualisierungswerkzeuge für den Imagekatalog der Musikabteilung der Staatsbibliothek zu Berlin
David Zellhöfer
Kernaspekte: OCR, Information Retrieval, Information Visualization, Linked Data
Der Alphabetische Imagekatalog der Musikabteilung umfasst ca. eine Million gescannte Katalogzettel, die mittels einer Web-Anwendung interessierten Nutzerinnen und Nutzer präsentiert werden. Um diese teils unikalen Bestände der Staatsbibliothek besser durchsuchbar zu machen, muss der Katalog mittelfristig einer Retrokonversion unterzogen werden. Ziel des Projektes ist es, geeignete Werkzeuge zu entwickeln, die sowohl Bibliothekarinnen und Bibliothekare sowie Nutzerinnen und Nutzer bei folgenden Tätigkeiten zu unterstützen:
- Überführung der teils handschriftlichen, mehrsprachigen Katalogscans in ein strukturiertes Datenformat, welches z.B. Signaturen, Komponisten oder Titel umfasst
- Durchsuchung des erzeugten, fehlerhaften Datenbestands mittels geeigneter Information-Retrieval-Algorithmen
- Visualisierung des entstandenen Datenraums z.B. mittels Cluster-Algorithmen, um ähnliche Datensätze darzustellen
- Präsentation der Arbeitsergebnisse mittels einer Web-Anwendung, die gängigen Usability- und Accessibility-Anforderungen genügt
Um die vier Aufgabengebiete zu bearbeiten bietet sich der Einsatz folgender Technologien an bzw. sind folgende Anforderungen denkbar.
Aufgabengebiet 1
- Mustererkennung und Segmentierung, um bestimmte Bereiche auf einem Katalogzettel seiner Funktion (z.B. Signaturnummer) zuzuordnen
- Training und Anpassung von OCR-Software (z.B. Tesseract OCR) aufgrund der Mehrsprachigkeit und der teils handschriftlichen Beschriftung der Zettel
- Plausibilitätsüberprüfung der zu erwartenden OCR-Ergebnisse durch den Abgleich mit bibliothekarischen Normdaten (z.B. Existenz des Komponistennamens)
- Speicherung dieser Daten in maschinenlesbaren Form
Aufgabengebiet 2
- Aufbau eines Information-Retrieval-Systems (z.B. SOLR oder ElasticSearch), welches mit den erzeugten, fehlerbehafteten Daten umgehen kann
- Bereitstellung gängiger Informationssuche-Strategien wie Faceted Navigation, Browsing und Keyword/Bag-of-Words-Queries
- Evaluierung des Systems
Aufgabengebiet 3
- Clustering der entstandenen Daten nach verschiedenen Ähnlichkeitskriterien (z.B. Schreibung des Komponisten), um falsch erkannte Datensätze einfach korrigieren zu können oder verwandten Aufnahmen zu finden (vgl. der „Meinten Sie…“-Funktion von Google)
- Untersuchung möglicher Explorationsmöglichkeiten des entstandenen Datenraums
- Web-basierte Präsentation der Cluster-Visualisierung und Ermöglichung der Editierung bereits bestehender Datensätze
Aufgabengebiet 4
- Präsentation der Ergebnisse mittels einer Web-Anwendung (kein Java, kein Flash) für Nutzerinnen und Nutzer der Staatsbibliothek
- Implementierung einer internen Web-Anwendung, welche die Bearbeitung und Exploration der erzeugten Daten ermöglicht
Für die Staatsbibliothek zu Berlin hat das Projekt einen deutlich experimentellen, forschungsnahen Charakter, d.h. dass uns bewusst ist, welche Probleme gerade die Erkennung von handgeschriebenen Katalogzetteln bereitet. Um trotzdem alle vier Aufgabengebiete bearbeiten zu können, bietet es sich deshalb an, zuerst mit maschinengeschriebenen Katalogzetteln zu beginnen und sich dann nach und nach an die komplizierten Zettel heranzuwagen. Die Betreuung seitens der Staatsbibliothek erfolgt primär durch den Referatsleiter IDM 2, David Zellhöfer, so dass eine wissenschaftliche Betreuung des Projekts im Bereich Information Retrieval und Informationsvisualisierung gewährleistet werden kann.
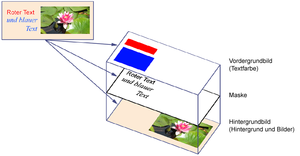
Automatische Segmentierung von Dokumenten
Prof. Klaus Jung
Bei der Archivierung von Dokumenten werden große Mengen an Papiervorlagen (Briefe, Bücher usw.) digitalisiert. Das geschieht durch Scannen oder Abfotografieren. Als digitales Dokument wird meistens ein PDF erzeugt, das die Seiten als JPEG-Bild enthält. JPEG eignet sich aber nicht gut für die Textanteile der Seiten. Daher sind solche PDFs entweder sehr groß oder von schlechter Qualität im Textanteil. Eine Abhilfe schafft die Mixed-Raster-Content Verarbeitung. Hierfür ist es notwendig, die Seiten zu segmentieren, d.h. in Text- und Bildanteile zu unterteilen. Diese Bereiche werden dann im PDF mit geeigneten Bildkompressionsverfahren eingebettet. Ziel dieses Projektes ist es, im ersten Semester geeignete Segmentierungsverfahren zu finden. Dazu sollen Ansätze aus der Objekterkennung/-klassifizierung untersucht werden. Im zweiten Semester können diese Verfahren dann in eine konkrete Anwendung eingebaut werden, die es dem Anwender erlaubt, hochqualitative und hochkomprimierte PDF-Dokumente aus Dokumentenaufnahmen zu erzeugen. Auch eine mobile Anwendung ist denkbar.
Crowd Simulation
Prof. Tobias Lenz
Wann immer es um Menschenmassen (crowds) geht, ist man heute versucht, diese vom Computer simulieren zu lassen: Im Kino spart man tausende von Statisten, im Sicherheitsbereich kann man Katastrophenszenarien simulieren und besser abschätzen und bei Computerspielen will man eine realistische Umgebung schaffen, ohne tausende von Individuen simulieren zu müssen. Die verwendeten Techniken sind dabei in den einzelnen Bereichen nicht so unterschiedlich, allerdings wird im Spielebereiche häufig Realismus gegen Geschwindigkeit eingetauscht. Deshalb ist dieser Bereich für uns besonders spannend. Wie kann man einem Spieler mit wenig Resourcenaufwand den kurzlebigen Eindruck einer belebten Metropole vorgaukeln? Diese Frage soll in Form eines mit Unity oder UE4 zu erstellenden Prototyps beantwortet werden, der im ersten Semester elementare Funktionen beinhaltet, die im zweiten Semester ausgebaut werden.
Interactive Sound Environment
Prof. Carsten Busch und Sabine Claßnitz
Schwerpunkte: Sound, Sensorik und Interaktion
Software: Webtechnologie, Web-Audio-API
Hardware: Ultraschallsensoren, RasPi, eventuell MS Kinect 2 und oder weitere Sensoren
Konzept: Auditive Interaktion mit Hilfe von Sensoren und mittels parametrisierter Klangerzeugung
Aufgaben:
- Klangerzeugung
- Synthesizer (mono- / polyphon)
- sample-basiert
- Interaktionskonzepte / Manipulation durch Einsatz von Sensorik
- Visualisierung mit Hilfe von Monitor und Lichtquellen (bspw. DMX-Leuchten)
- Recherche und Wissenstransfer des derzeitigen Stands der Technik (und Wissenschaft) zu Echtzeitsoundverarbeitung und -erzeugung